
JCF (Java Collection Framework)의 List 인터페이스를 구현한 ArrayList와 LinkedList는 순서가 지정된 컬렉션(Sequence)라는 점에서 공통점을 가지고 있다. 또한 List 인터페이스가 제공하는 메서드를 동일하게 수행할 수 있다.
그렇다면 어떤 기준으로 자료구조를 선택해야할까? 기본적으로 알고리즘 분석을 통해서 선택할 수 있다. 주요 메서드를 구현 및 분석해보고, 상황에 따라 적절한 알고리즘을 살펴보자.
ArrayList
https://docs.oracle.com/javase/8/docs/api/java/util/ArrayList.html 문서를 기반으로 ArrayList 클래스를 살펴보고, 구현해보자.
ArrayList (Java Platform SE 8 )
Resizable-array implementation of the List interface. Implements all optional list operations, and permits all elements, including null. In addition to implementing the List interface, this class provides methods to manipulate the size of the array that is
docs.oracle.com
ArrayList는 배열로 List 인터페이스를 구현한 클래스다. 자바에서 배열의 크기는 변경할 수 없기 때문에, 내부적으로 배열의 크기를 변경하는 메서드를 제공한다. 데이터가 추가되면 자동으로 배열의 크기가 늘어나게 된다.
생성자
public class MyArrayList<E> implements List<E> {
E[] array; // 데이터를 저장할 배열
int size; // 배열에 저장된 데이터의 갯수
public MyArrayList() {
array = (E[]) new Object[10];
size = 0;
}
// 이하 메서드 생략
}
ArrayList 생성자는 기본적으로 초기 용량이 10인 배열을 생성한다. 자바에서는 타입 파라미터로 배열을 초기화 할 수 없으므로, Object 배열로 초기화하고 형변환(type casting)을 해야한다. 다만 이 클래스에서는 size 메서드를 구현하는 대신 size 필드를 생성하여 활용할 것이다.
ensureCapacity
public void ensureCapacity(int minCapacity) {
E[] bigger = (E[]) new Object[minCapacity];
System.arraycopy(array, 0, bigger, 0, array.length);
array = bigger;
}
List 인터페이스 이외에도 배열의 크기를 늘리는 ensureCapacity를 구현해야 한다. 파라미터로 받은 minCapacity만큼의 배열을 새롭게 생성하고, 요소를 복사한다.
System.arrayCopy() 메서드에서 배열의 크기만큼 요소를 복사하므로 O(n)의 시간복잡도를 가지게 된다.
add
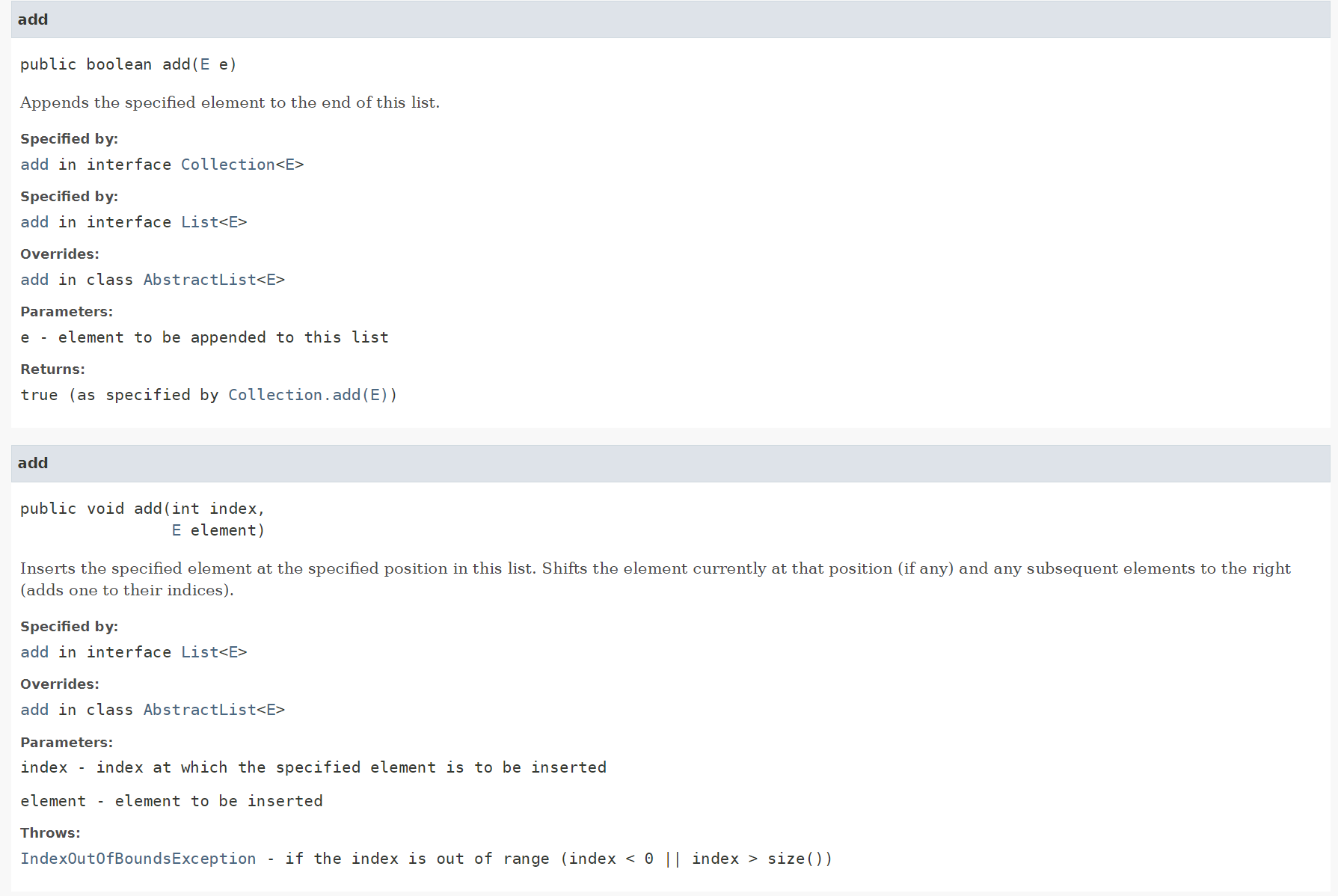
@Override
public boolean add(E e) {
if (size >= array.length) {
ensureCapacity(array.length * 2);
}
array[size] = e;
size++;
return true;
}
@Override
public void add(int index, E element) {
if (index < 0 || index > size) {
throw new IndexOutOfBoundsException();
}
add(element);
for (int i = index; i < size; i++) {
array[i + 1] = array[i];
}
array[index] = element;
}
add(E e)의 worst case의 경우에는 ensureCapacity가 실행되기 때문에 O(n)의 시간복잡도를 가진다. 상수는 고려하지 않는다.
add(int index, E element)의 경우 중복된 코드를 피하기 위해 먼저 O(n)의 add(element)를 호출한다. 이후 인덱스를 정렬하기 위해 for문을 호출하는데, index가 0인 worst case의 경우 시간 복잡도가 O(n)이 된다. 시간 복잡도에서 계수는 고려하지 않으므로 마찬가지로 시간 복잡도는 O(n)이 된다.
* add(E e) 메서드가 boolean을 반환하는 이유는 List 인터페이스를 구현할 때 중복된 요소를 허용하지 않는 경우 false를 반환하기 위해서다. ArrayList의 경우 중복 요소에 대한 제한이 없으므로 true를 반환한다.
https://docs.oracle.com/javase/8/docs/api/java/util/Collection.html#add-E-
** 상환 분석을 통한 add의 성능 분석이 궁금하다면 아래 링크에 포함된 예시를 참고.
2023.11.22 - [Java/알고리즘] - [알고리즘] 알고리즘 성능을 분석하는 상환 분석 (Amortized Analysis)
indexOf
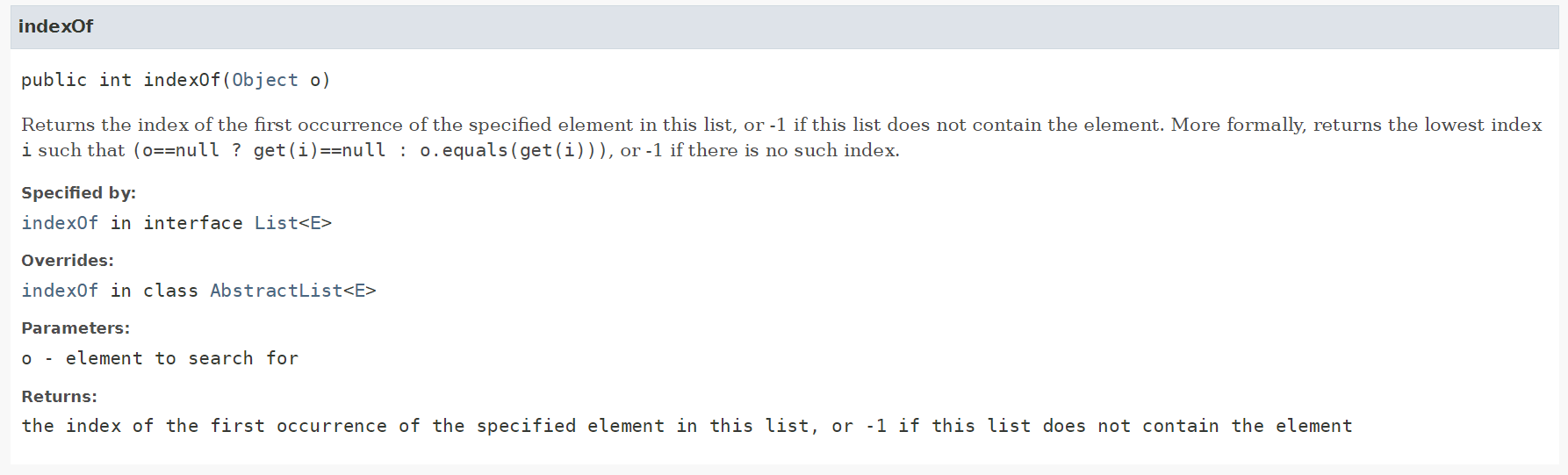
@Override
public int indexOf(Object o) {
for (int i = 0; i < size; i++) {
if (o == null) {
if (array[i] == null) {
return i;
}
} else {
if (o.equals(array[i])) {
return i;
}
}
}
return -1;
}
indexOf() 메서드의 경우 null 데이터에 유의해서 코드를 구현해야한다. worst case의 경우 for문 전체를 돌게 되므로 O(n)의 시간복잡도를 가진다.
remove

@Override
public boolean remove(Object o) {
int index = indexOf(o);
if (index == -1) {
return false;
}
for (int i = index; i < size; i++) {
array[i] = array[i + 1];
}
size--;
return true;
}
삭제를 위해서는 데이터에 직접 접근하는 것이 아니라, 인덱스를 왼쪽으로 하나씩 옮기는 방법을 사용한다. 따라서 O(n)의 시간복잡도를 가진다.
get / set
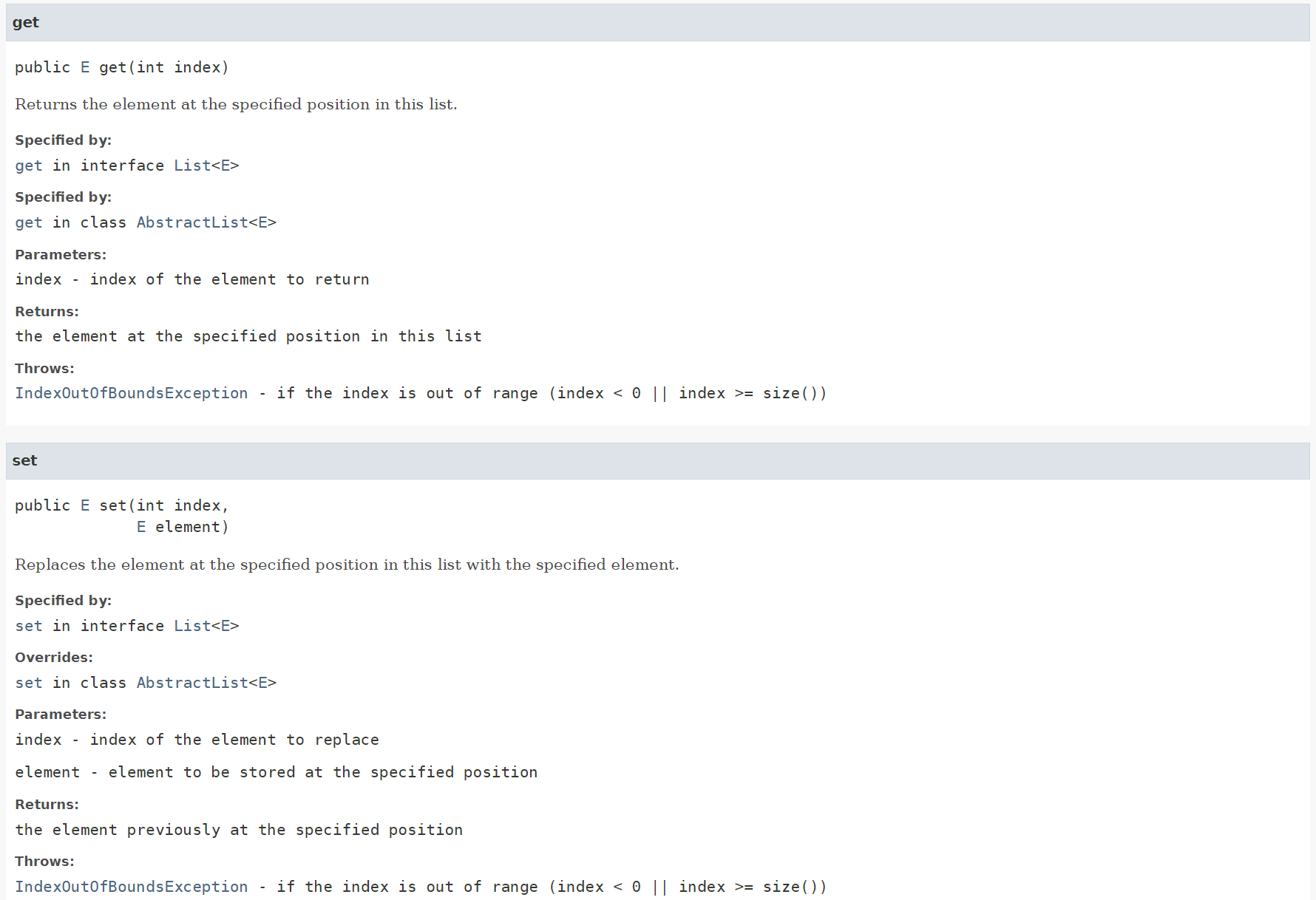
@Override
public E get(int index) {
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException();
}
return array[index];
}
@Override
public E set(int index, E element) {
E preElement = get(index);
array[index] = element;
return preElement;
}
get()과 set()의 경우 ArrayList의 크기에 상관없이 인덱스를 통해 접근하므로 O(1)의 시간복잡도를 가진다.
LinkedList
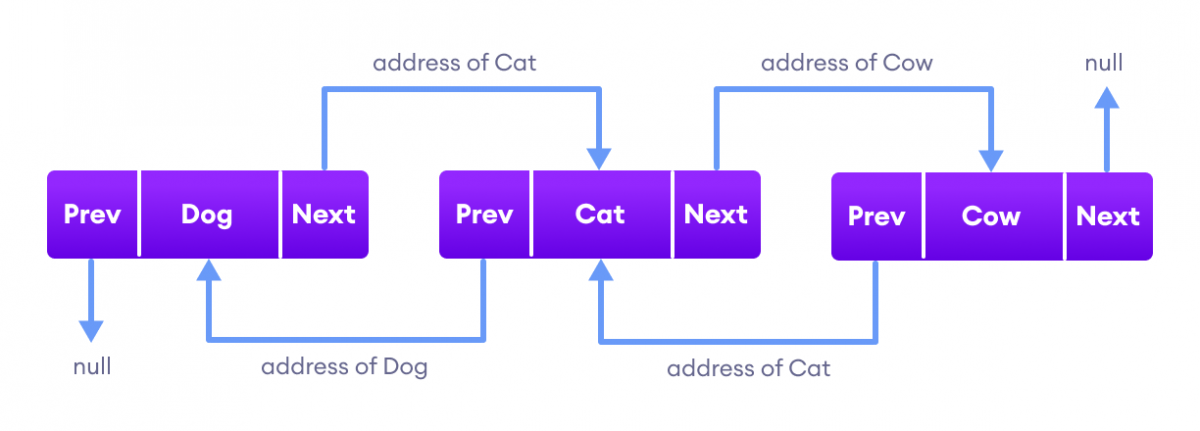
https://docs.oracle.com/javase/8/docs/api/java/util/LinkedList.html 을 기반으로 LinkedList를 살펴보고 구현할 것이다.
LinkedList (Java Platform SE 8 )
Returns a list-iterator of the elements in this list (in proper sequence), starting at the specified position in the list. Obeys the general contract of List.listIterator(int). The list-iterator is fail-fast: if the list is structurally modified at any tim
docs.oracle.com
생성자
public class MyLinkedList<E> implements List<E> {
private class Node {
E data;
Node prev;
Node next;
public Node (E data) {
this.data = data;
prev = null;
next = null;
}
public Node (E data, Node prev, Node next) {
this.data = data;
this.prev = prev;
this.next = next;
}
}
Node head; // 첫번째 노드
Node tail; // 마지막 노드
int size; // 배열에 저장된 데이터의 갯수
public MyLinkedList() {
head = null;
tail = null;
size = 0;
}
// 메서드 생략
}
자바에서 LinkedList는 Doubly-LinkedList다. 즉, 데이터 + 이전 데이터의 주소를 참조하는 prev + 다음 데이터의 주소를 참조하는 next로 노드를 구성한다.
add

@Override
public boolean add(E e) {
if (head == null) {
head = new Node(e, null, null);
tail = head;
} else {
Node node = tail;
tail = new Node(e, tail, null);
node.next = tail;
}
size++;
return true;
}
@Override
public void add(int index, E element) {
if (index < 0 || index > size) {
throw new IndexOutOfBoundsException();
}
if (index == 0) {
head.prev = new Node(element, null, head);
head = head.prev;
} else if (index == size) {
tail.next = new Node(element, tail, null);
tail = tail.next;
} else {
Node node = null;
if (Math.abs(0 - index) <= Math.abs(index - size)) {
node = head;
for (int i = 0; i < index; i++) {
node = node.next;
}
} else {
node = tail;
for (int i = 0; i < size - index; i++) {
node = node.prev;
}
}
node.prev.next = new Node(element, node.prev, node);
node.prev = node.prev.next;
}
size++;
}
이중연결리스트는 양방향 액세스를 허용하므로, 리스트의 인덱스를 활용하는 연산은 head와 tail 중 가까운 부분부터 리스트를 순회한다. 처음과 끝에 데이터를 추가할 경우 시간복잡도는 O(1)이지만, worst case는 O(n)이 된다.
indexOf

@Override
public int indexOf(Object o) {
Node node = head;
int index = 0;
while (node.next != null) {
if ((o == null && node.data == null) || (o != null && o.equals(node.data))) {
return index;
}
index++;
node = node.next;
}
return -1;
}
worst case는 list 전체를 순회하고도 해당되는 데이터가 없어 -1을 반환하는 경우이다. 이 경우 O(n)의 시간복잡도를 가지게 된다.
remove
@Override
public boolean remove(Object o) {
int index = indexOf(o);
if (index == -1) {
return false;
}
remove(index);
return true;
}
@Override
public E remove(int index) {
Node node = null;
if (index == 0) {
node = head;
head = head.next;
head.prev = null;
} else if (index == size - 1) {
node = tail;
tail = tail.prev;
tail.next = null;
} else {
if (Math.abs(0 - index) <= Math.abs(index - size)) {
node = head;
for (int i = 0; i < index; i++) {
node = node.next;
}
} else {
node = tail;
for (int i = 0; i < size - index; i++) {
node = node.prev;
}
}
node.prev.next = node.next;
}
size--;
return node.data;
}
indexOf()와 remove(int index)가 각각 O(n)의 복잡도를 가지므로 remove(Objext o)는 O(n)의 시간복잡도를 가진다.
get / set
@Override
public E get(int index) {
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException();
}
Node node = null;
if (Math.abs(0 - index) <= Math.abs(index - size)) {
node = head;
for (int i = 0; i < index; i++) {
node = node.next;
}
} else {
node = tail;
for (int i = 0; i < size - index; i++) {
node = node.prev;
}
}
return node.data;
}
@Override
public E set(int index, E element) {
if (index < 0 || index >= size) {
throw new IndexOutOfBoundsException();
}
Node node = null;
if (Math.abs(0 - index) <= Math.abs(index - size)) {
node = head;
for (int i = 0; i < index; i++) {
node = node.next;
}
} else {
node = tail;
for (int i = 0; i < size - index; i++) {
node = node.prev;
}
}
E data = node.data;
node = new Node(element, node.prev, node.next);
return data;
}
LinkedList가 인덱스를 사용하기 위해서는 리스트를 순회하는 작업이 필요하므로 시간복잡도는 O(n)이다.
ArrayList vs LinkedList
이때까지의 시간 복잡도를 정리해보자.
| ArrayList | LinkedList | |
| add | n | n |
| remove | n | n |
| indexOf | n | n |
| get / set | 1 | n |
ArrayList는 인덱스를 이용해 데이터를 접근하는 get / set 의 시간복잡도가 낮으므로, 해당 메서드를 빈번하게 사용하는 알고리즘의 경우 ArrayList를 이용하는 것이 효율적이다.
그렇다면 LinkedList는 이점이 없는걸까? 아니다.
| ArrayList | LinkedList | |
| add(처음) | n | 1 |
| add(끝) | 1 | 1 |
| remove(처음) | n | 1 |
| remove(끝) | 1 | 1 |
ArrayList의 경우 데이터를 추가하거나 제거할 때 인덱스를 정렬해야하지만, LinkedList의 경우 연결 Node만 수정하면 되므로 효율적이다. 따라서 처음이나 끝 근처에 요소를 추가하거나 제거하는 작업이 빈번하다면 LinkedList를 선택하는 것이 시간면에서 이득이다.
***
이상으로 알고리즘 분석을 통해 ArrayList와 LinkedList를 비교해보았다. 하지만 주의할 점이 있다. 응용 프로그램의 실행시간이 다른 작업을 하느라 대부분의 시간을 소모하면 List 구현에 대한 선택은 큰 의미가 없다. 또한 작업하는 리스트가 매우 크지 않으면 기대하는 성능을 얻기 어려운 경우도 많다. 작은 문제에서는 차이가 그리 중요하지 않기 때문이다.
또한 메모리상에 연속되어 데이터를 저장하는 ArrayList와 비교했을 때, LinkedList는 메모리 여기저기에 노드가 흩어져있을 수 있으며 참조를 위한 공간을 차지하기도 한다. 따라서 단순히 알고리즘 분석에만 의존하지 않고 상황에 따라 적절한 자료구조를 선택하는 것이 필요하다.
'Backend > Java-Spring' 카테고리의 다른 글
| [eclipse] xml파일의 "Downloading external resources is disabled." 오류 해결 (0) | 2024.04.28 |
|---|---|
| [Java] 클래스.toString()을 public으로 선언해야 하는 이유 (3) | 2024.01.18 |
| [알고리즘] 알고리즘 성능을 분석하는 상환 분석 (Amortized Analysis) (1) | 2023.11.22 |
| [Java] 추상클래스와 인터페이스의 비교 (2) | 2023.10.17 |
| [Java] 연속된 부분 배열의 최대 합 구하기 (1) | 2023.10.08 |



